Light Up the Shadows: Enhance Long-Tailed Entity Grounding with Concept-Guided Vision-Language Models
Published in ACL(Findings), 2024
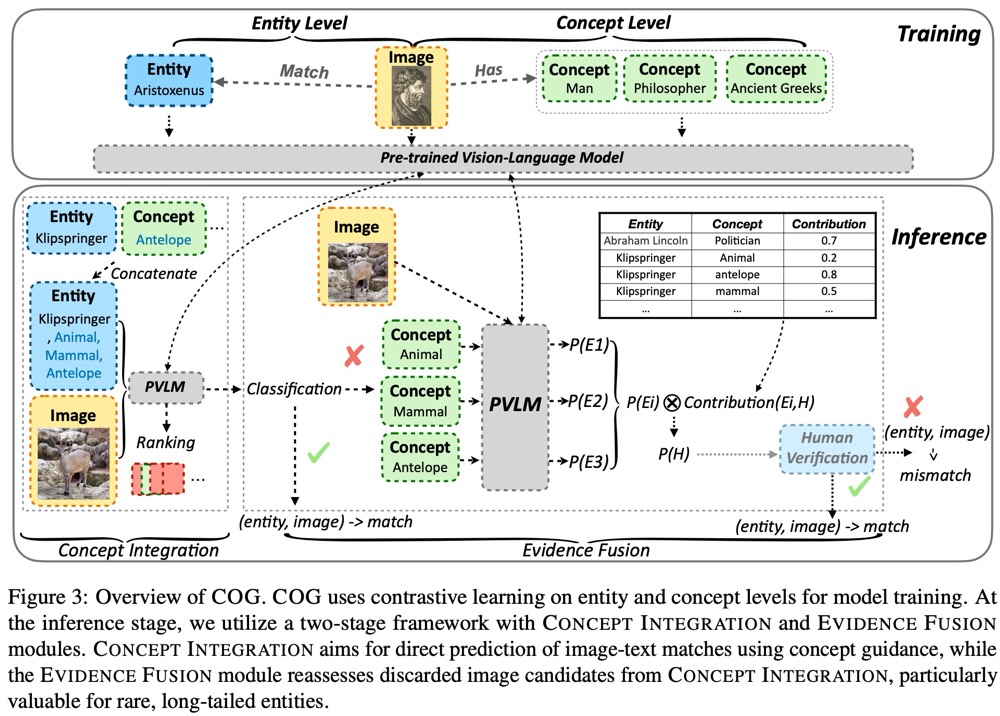
Multi-Modal Knowledge Graphs (MMKGs) have proven valuable for various downstream tasks. However, scaling them up is challenging because building large-scale MMKGs often introduces mismatched images (i.e., noise). Most entities in KGs belong to the long tail, meaning there are few images of them available online. This scarcity makes it difficult to determine whether a found image matches the entity. To address this, we draw on the Triangle of Reference Theory and suggest enhancing vision-language models with concept guidance. Specifically, we introduce COG, a two-stage framework with COncept-Guided vision-language models. The framework comprises a Concept Integration module, which effectively identifies image-text pairs of long-tailed entities, and an Evidence Fusion module, which offers explainability and enables human verification. To demonstrate the effectiveness of COG, we create a dataset of 25k image-text pairs of long-tailed entities. Our comprehensive experiments show that COG not only improves the accuracy of recognizing long-tailed image-text pairs compared to baselines but also offers flexibility and explainability.